ChatWiz
November 13, 2023
(Github Link, Devpost Link)
Background
This project was made in 24 hours during Madhacks (ephemeral link, devpost, github), a hackathon ran by the UW UPL. I came into the event with minimal knowledge of web technologies, so my teamate Jerry handled all of the architectural and technical aspects. My main role was to analyze pre-existing code (written by Jerry, documentation, GPT, or otherwise), and extrapolate it: i.e. fill in the boilerplate. This worked better than I expected (I’ve picked up enough small details to be able to get an idea of what the code does), but I introduced more bugs that I’d care to admit.
Motivation
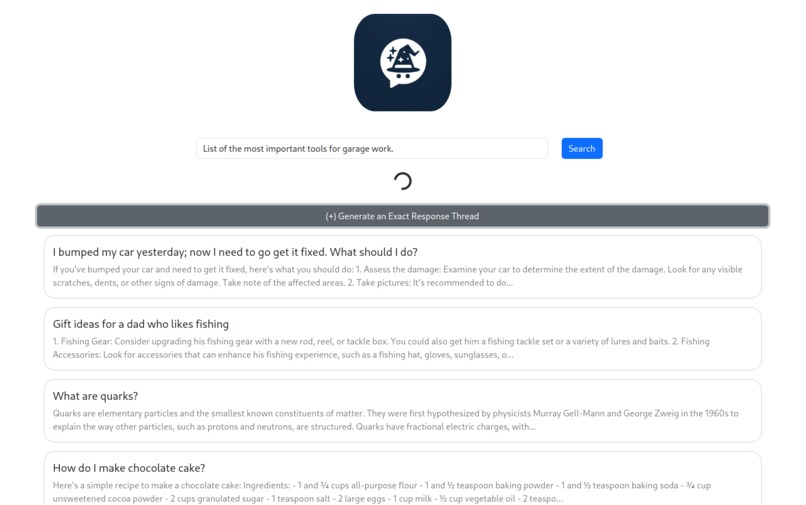
The most popular publicly-avaiable LLMs all have the same format: chat conversations. This format is useful for very specific questions, but it can be time-consuming and computationally expensive to narrow down its responses to generalized questions. Sometimes LLMs can generate a wide array of responses to a single question, some of which may be objectively of higher quality. Using a chat-format forces users to choose between accepting a roll of the dice or waiting for multiple responses to be generated.
ChatWiz aims to solve these problems by creating a similarity-searchable database of questions, each with multiple generated responses, ranked by users.
Architecture
The back-end (NodeJS) manages the database (MongoDB Atlas), user authentication (custom JWT authentication written by Jerry), and calls to OpenAI’s API. It exposes a REST API (ExpressJS) that encapsulates those functionalities.
The front-end (ReactJS) makes requests (Axios) to that API. Style is done with Bootstrap.
Vector Search
Similarity-search is the most technically nuanced part of this project. Each question in the database is given an embedding: this is a high-dimensional numeric vector that represents the semantic meaning of the question (rather than the literal text-contents). The dot-product of two embedding vectors can be taken to determine the similarity of two questions. The vector search algorithm takes a question embedding and returns questions whose embeddings are similar to the input.
The actual embedding and vector search algorithms are done by Mongo DB Atlas, but the storage of the embedding and fine-tunings of the algorithm’s inputs are handled by the backend.